Why this project exists
Fine-tuning language models is expensive in the places that matter for edge or local deployment: trainable parameters, memory footprint, and high-quality task data. We use GPT-2 Small as a micro-scale proxy and ask a sharper question: which efficiency knobs preserve quality under tight constraints, and where do they quietly fail?
Sonnet generation is the stress test because it is open-ended, structured, and unforgiving. Sentiment classification and paraphrase detection anchor the baselines, while sonnets expose whether the model can retain style, syntax, and form after adaptation.
Setup and baseline
We fine-tune GPT-2 on sentiment classification, paraphrase detection, and Shakespearean sonnet generation. The first two tasks provide standard supervised baselines. Sonnet generation is the harder test because it requires longer-form, structured output and makes degradation easier to spot.
| Task | Method | Metric | Dev | Test |
|---|---|---|---|---|
| SST sentiment | Full fine-tuning | Accuracy | 0.513 | 0.546 |
| CFIMDB sentiment | Full fine-tuning | Accuracy | 0.971 | — |
| Quora paraphrase | Full fine-tuning | Accuracy | 0.911 | 0.891 |
| Sonnet generation | Full fine-tuning | chrF | 41.974 | 41.078 |
Important caveat: the sonnet held-out sets are tiny. The reported sonnet test score is measured on only 12 examples, so one unusually good or bad generation can move the final number noticeably.
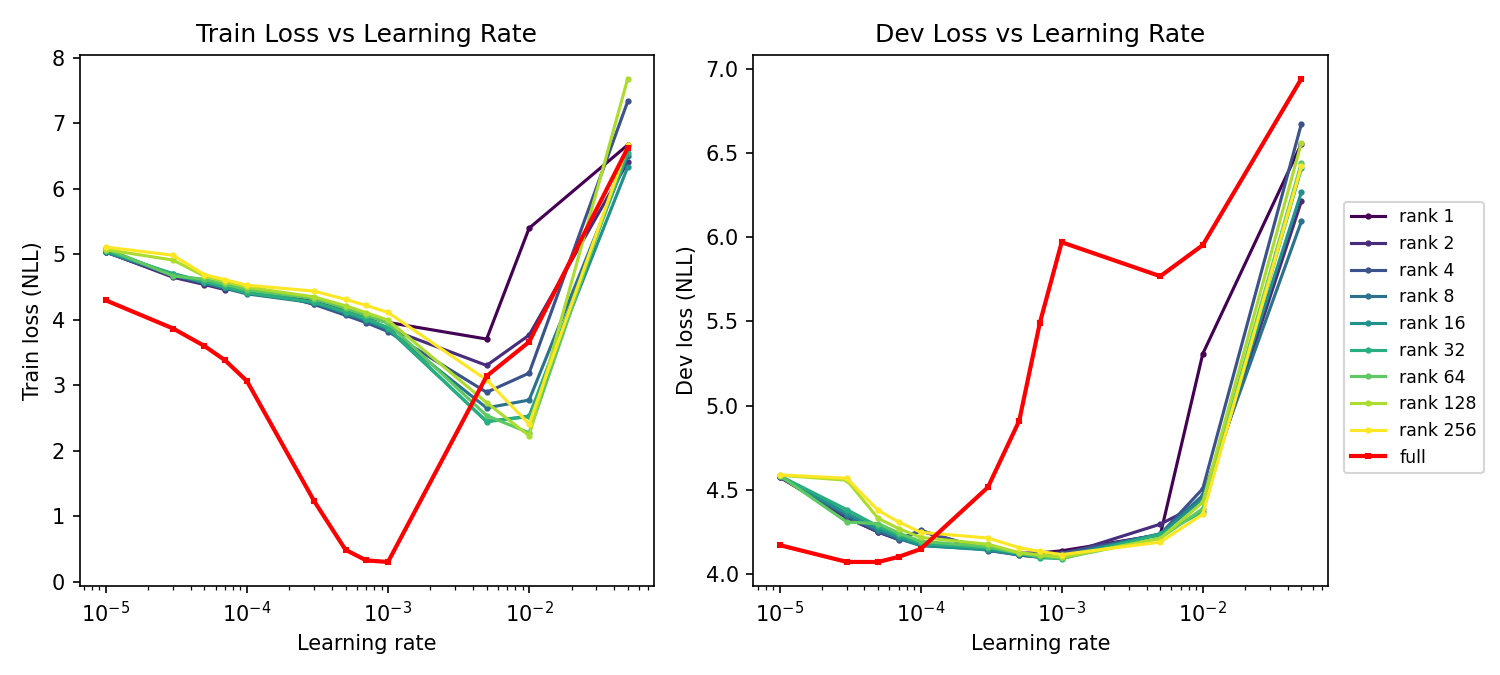
Takeaway 1 — LoRA matches full fine-tuning with far fewer trainable weights
LoRA is the most straightforward efficiency result in the paper. Rank 256 uses about 42.5M trainable parameters instead of updating the full 124M-parameter GPT-2 Small model, and ranks 1–128 all stay within about one chrF point of full fine-tuning. For sonnets, GPT-2 seems to need a targeted style nudge more than a full rewrite of its weights.
- Best configuration: rank 256, alpha 16, learning rate 1e-2
- Rank 256 trains about 42.5M parameters, compared with 124M in full fine-tuning
- Applying LoRA to attention and MLP layers outperforms attention-only tuning
- Best dev chrF: 42.158, slightly above full fine-tuning
Takeaway 2 — Quantization preserves the target task while damaging generality
Lower precision can make GPT-2 much smaller: the paper plots FP64, FP32, BF16, FP8, INT8, and INT4 settings against sonnet chrF and model size. QAFT recovers much of the sonnet score at low precision, but the zero-shot check shows the catch: paraphrase accuracy falls sharply after INT8 QAFT.
.png)
.png)
Takeaway 3 — Synthetic data helps, but a stronger teacher is not always better
The original sonnet dataset is tiny. To expand it, we prompt Gemini 2.5 Flash Lite, Flash, and Pro to generate up to 1,000 Shakespearean sonnets, then use those synthetic samples for distillation-style fine-tuning. The results are the paper's most interesting finding: quality, cost, and student capacity interact in a non-obvious way.
Gemini 2.5 Flash gives the strongest GPT-2 gains, while Gemini 2.5 Pro generates structurally strong sonnets but does not transfer best to the small student. A more capable teacher can still be a worse fit.
.png)
| Teacher | Perfect sonnet rate | Takeaway |
|---|---|---|
| Gemini 2.5 Flash Lite | 56% | Cheapest, but low enough quality that more data can hurt |
| Gemini 2.5 Flash | 72% | Best downstream fit for GPT-2 Small |
| Gemini 2.5 Pro | 75% | Most structurally valid, but not the best student result |
- Flash Lite is cheap, but only 56% of its sonnets pass the automated 14-line plus rhyme check. Adding more of that data does not help GPT-2.
- Flash reaches a 72% perfect-sonnet rate and produces the strongest student result — it lands in the useful middle: better structure without overwhelming the student.
- Pro has the highest automated validity rate at 75%, but its 1,000-example run trails Flash. That points to capacity mismatch rather than simple data quality.
Best dev chrF: 46.605. Best test chrF: 52.838 (12-sonnet test set). Up from 41.078 at full fine-tuning baseline.