The task
Crop yield prediction is a field-level regression problem. For each agricultural field, we observe a growing-season sequence of satellite images and predict one yield value. The raw data can be difficult to work with, but combining satellite imaging with multi-modal field features, this can become an advanced time-series problem. We can incorporate state of the art satellite foundation models (dinov3-vit7b16-pretrain-sat493m[2]) with time-series transformers to complete this task.
The project uses the YieldSAT dataset across Argentina, Brazil, Uruguay, and Germany. The core modeling question is simple: can we reuse a strong satellite vision backbone to avoid learning all spatial features from scratch, then spend the supervised signal on the temporal yield problem?
The architecture
The main model separates representation learning from yield regression. Each image is encoded independently by a DINOv3 model, and the resulting sequence of embeddings is passed into a time-series transformer. In symbols, each field has images \(x_{i,1}, \ldots, x_{i,T}\), and each image becomes a compact vector \(z_{i,t}\):
12-band Sentinel-2 image
-> learned 12-to-3 channel adapter
-> DINOv3 ViT-7B satellite backbone
-> pooled DINOv3 vector in R^4096
-> MLP, 4096 GeLU -> 4096 -> 256
-> per-image embedding z_t in R^256
-> time-series transformer
-> scalar yield prediction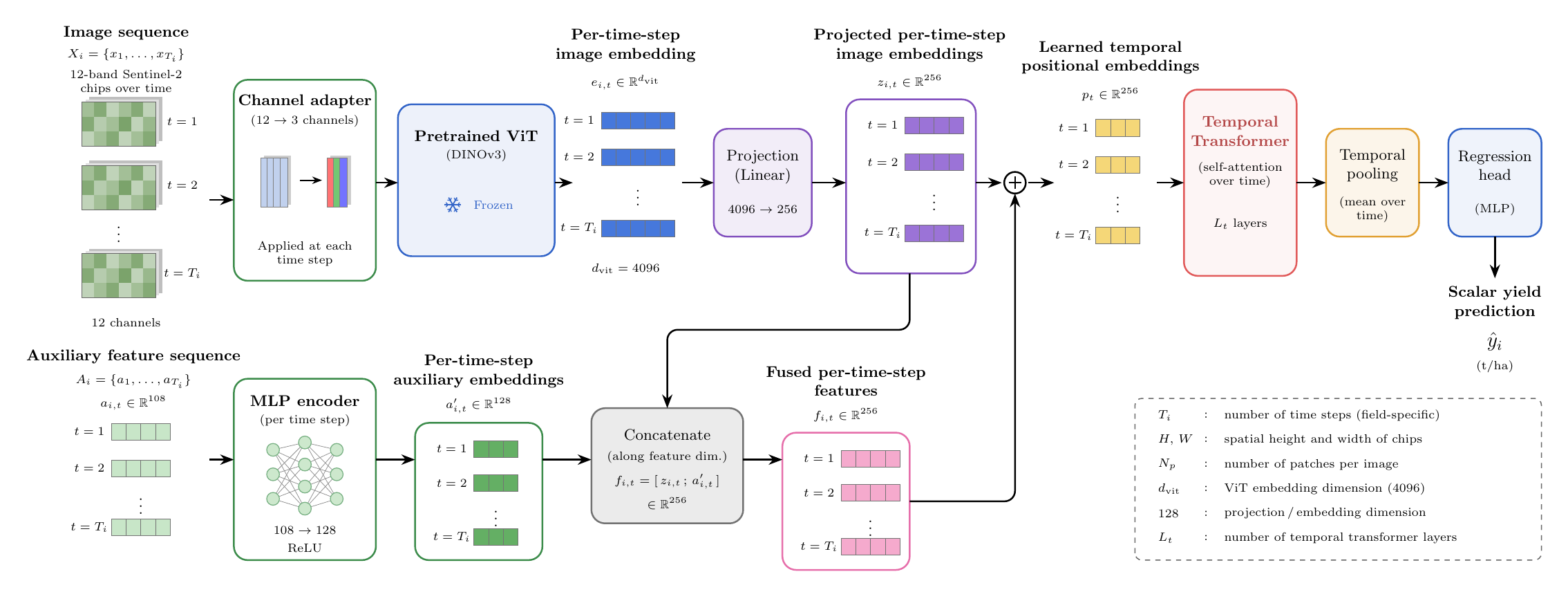
The pipeline
The data and training jobs run on Modal volumes. Raw imagery lives in the yield-sat volume, while checkpoints and exported SSL embeddings live in yield-sat-checkpoints. The workflow is:
- Resize raw Sentinel-2 chips to 224 by 224 while preserving all 12 bands.
- Train or load the ViT SSL checkpoint.
- Export one 256-D embedding per field image.
- Build field-level yield targets from raw metadata.
- Train a temporal regressor over the saved embedding sequences.
modal run modal_jobs/export_best_embeddings_modal.py::export_best_embeddings \
--countries Argentina,Brazil,Uruguay,Germany
uv run python modal_jobs/train_timeseries_transformer.py \
--embeddings-root downloads/final_embeddings_best_full/Argentina \
--targets-path targets/targets_argentina.json \
--country Argentina \
--batch-size 8 \
--epochs 20 \
--context-length 32What we compared
We evaluate the ViT temporal-transformer pipeline against baselines that either use preprocessed time-series features or learn directly from raw imagery. The most important comparison is between the all-feature preprocessed LSTM and the ViT model, because both are available across all four countries.
| Model | Input / adapter | Arg. RMSE | Arg. R2 | Bra. RMSE | Bra. R2 | Uru. RMSE | Uru. R2 | Ger. RMSE | Ger. R2 |
|---|---|---|---|---|---|---|---|---|---|
| ViT + temporal transformer | Linear projection | 0.610 | - | 1.522 | - | 0.838 | - | 2.399 | - |
| ViT + temporal transformer | MLP projection | 0.450 | 0.970 | 1.350 | 0.630 | 0.745 | 0.398 | 1.746 | 0.610 |
| Preprocessed LSTM | All features | 1.381 | 0.760 | 1.412 | 0.560 | 1.192 | 0.370 | 1.992 | 0.670 |
| 3D-CNN + TCN | Raw image baseline | 0.874 | - | 2.191 | - | 0.967 | - | 2.047 | - |
Additional baselines were run only on Argentina, so they should not be read as four-country comparisons. They are still useful because they probe the value of image information and different sequence architectures.
| Model | Input | Argentina RMSE |
|---|---|---|
| Preprocessed transformer | Non-image features | 1.866 |
| Preprocessed RNN | Non-image features | 1.835 |
| Preprocessed LSTM | Non-image features | 1.839 |
| ResNet50 + LSTM | Raw image baseline | 2.851 |
The original paper trains each country separately. We aggregate each country into 1 mixed dataset and compare our transformr-based approach to these other models when training on this dataset. Our findings are that our model has cleaner training dynamics:
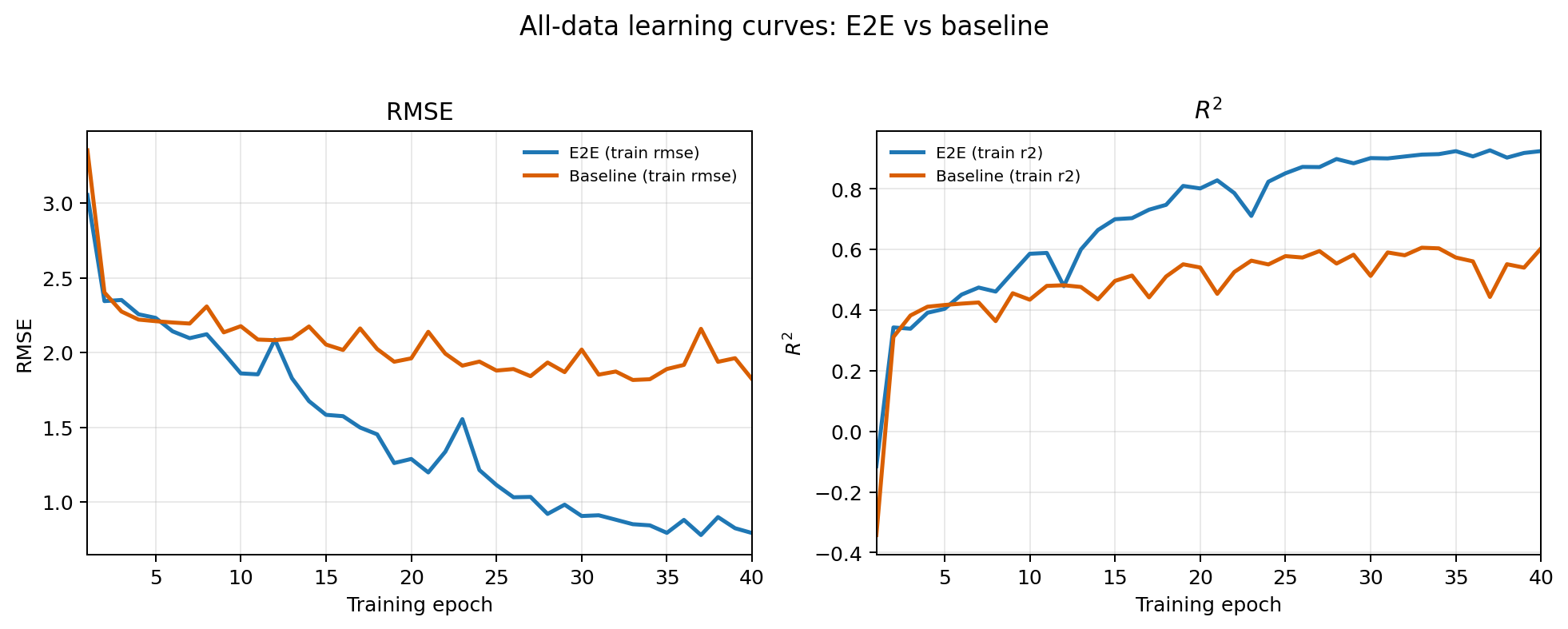
And can generalize better when all of these fields are aggregated:
| Model | Validation RMSE |
|---|---|
| Baseline 3D CNN-LSTM | 2.489 |
| 3D CNN-TCN | 2.172 |
| ViT + time-series transformer | 1.499 |
We think this is due to the ability of a foundational image encoder (DINOv3) to generalize better across all countries and crops.
What worked
The strongest ViT variant contains a single hidden layer adapter. We find that LoRA offers no gain (since our dataset isn't large enough), so training an MLP adapter is a better form of fine tuning DINOv3. It improves validation RMSE over the preprocessed LSTM in Argentina, Brazil, and Uruguay, and it substantially closes the gap on Germany. The gains are largest in Argentina, where the ViT model reaches 0.450 RMSE and \(R^2 = 0.970\).
The likely reason is that the frozen satellite backbone already contains useful spatial features: crop texture, field structure, vegetation patterns, and other states that a general CNN could learn. The temporal transformer then learns how those image states evolve over the season.
Takeaways
A clear takeaway is that foundational satellite models can learn important agricultural features that we can use. A large satellite ViT gives the temporal yield model a much better starting point than learning image features from scratch, and its base weights can remain frozen.
We also looked at saliency maps to understand what the image models were using inside a field. The maps below compare the ViT-based encoder and a ResNet-LSTM raw-image baseline on the same Argentina wheat field. Brighter regions indicate larger input or adapter gradients for the selected prediction target.


This qualitative comparison supports the quantitative result: the satellite foundation model appears to provide a richer spatial prior before the temporal transformer ever sees the sequence.
References
- Miro Miranda, Deepak Pathak, Patrick Helber, Benjamin Bischke, Hiba Najjar, Francisco Mena, Cristhian Sanchez, Akshay Pai, Diego Arenas, Matias Valdenegro-Toro, Marcela Charfuelan, Marlon Nuske, and Andreas Dengel. YieldSAT: A Multimodal Benchmark Dataset for High-Resolution Crop Yield Prediction. arXiv:2604.00940, 2026. arXiv · project page
- Meta AI. DINOv3 ViT-7B/16 pretrained on SAT-493M. Hugging Face model page. facebook/dinov3-vit7b16-pretrain-sat493m